Load Data from Amazon Web Services (AWS) S3
On this page
SingleStore Pipelines can extract objects from Amazon S3 buckets, optionally transform them, and insert them into a destination table.
Prerequisites
To complete this Quickstart, your environment must meet the following prerequisites:
-
AWS Account: This Quickstart uses Amazon S3 and requires an AWS account’s access key id and secret access key.
-
SingleStore installation –or– a SingleStore cluster: You will connect to the database or cluster and create a pipeline to pull data from your Amazon S3 bucket.
Part 1: Creating an Amazon S3 Bucket and Adding a File
-
On your local machine, create a text file with the following CSV contents and name it
books.:txt The Catcher in the Rye, J.D. Salinger, 1945 Pride and Prejudice, Jane Austen, 1813 Of Mice and Men, John Steinbeck, 1937 Frankenstein, Mary Shelley, 1818 -
In S3 create a bucket and upload
books.to the bucket.txt For information on working with S3, refer to the Amazon S3 documentation. Note that the
aws_that your SingleStore pipeline will use (specified in the next section inaccess_ key_ id CREATE PIPELINE library .) must have read access to both the bucket and the file.. . CREDENTIALS . . .
Once the books. file has been uploaded, you can proceed to the next part of the Quickstart.
Part 2: Generating AWS Credentials
To be able to use an S3 bucket within the pipeline syntax, the following minimum permissions are required:
-
s3:GetObject
-
s3:ListBucket
These permissions only provide for read access from an S3 bucket which is the minimum required to ingest data into a pipeline.
There are two ways to create an IAM Policy: with the Visual editor or JSON.
Create an IAM Policy Using the Visual Editor
-
Log into the AWS Management Console.
-
Obtain the Amazon Resource Number (ARN) and region for the bucket.
The ARN and region are located in the Properties tab of the bucket. -
Select IAM from the list of services.
-
Click on Policies under Access Management and click the Create policy button.
-
Using the Visual editor:
-
Click on the Service link and select S3 from the list or manually enter S3 into the search block.
-
Click on the S3 link from the available selections.
-
In the Action section, click the List and Read checkboxes.
-
Under Resources, click the bucket link and click on the Add ARN link.
Enter the ARN and bucket name and click the Add button. -
Under Resources, click the object link and click on the Add ARN link.
Enter the ARN and object name and click the Add button. If no objects are added under resources, the created policy has access to all objects in the bucket’s root path. -
Request conditions are optional.
-
Create an IAM Policy Using JSON
-
To use JSON for policy creation, copy the information in the code block below into the AWS JSON tab.
Make sure to change the bucket name. {"Version": "2012-10-17","Statement": [{"Sid": "VisualEditor1","Effect": "Allow","Action": ["s3:GetObject","s3:ListBucket"],"Resource": ["arn:aws:s3:::<bucket_name>","arn:aws:s3:::<bucket_name>/*"],"Conditions": {"StringNotEquals": {"aws:SourceVpce": "<vpc - id>"}}}]} -
Click the Add tag button if needed and click Next: Review.
-
Enter a policy name this is a required field.
The description field is optional. Click Create policy to finish.
Assign the IAM Policy to a New User
-
In the IAM services, click on Users and click the Add users button.
-
Enter in a name for the new user and click Next.
-
Select the Attach policies directly radio button.
Use the search box to find the policy or scroll through the list of available policies. -
Click the checkbox next to the policy to be applied to the user and click Next.
-
Click the Create user button to finish.
Create Access Keys for Pipeline Syntax
Access keys will need to be generated for the newly created user.
-
In the IAM services, click on Users and click the newly created user name.
-
Click on the Security credentials tab.
-
In the access keys section, click on the Create access key button.
-
Click on the Third-party service radio button and click Next.
-
Although setting a description tag is optional, SingleStore recommends especially when multiple keys are needed.
Click the Create key button to continue. -
At the final screen there will be an option to download a
.file with the access and secret key access information or to copy the information.csv Click Done when finished. -
Below is the basic syntax for using an access key and a secret access key in a pipeline:
CREATE PIPELINE <pipeline_name> ASLOAD DATA S3 's3://bucket_name/<file_name>'CONFIG '{"region":"us-west-2"}'CREDENTIALS '{"aws_access_key_id": "<access key id>","aws_secret_access_key": "<access_secret_key>"}'INTO TABLE <destination_table>FIELDS TERMINATED BY ',';
Warning
If the key information is not downloaded or copied to a secure location before clicking Done, the secret key cannot be retrieved, and will need to be recreated.
Part 3: Creating a SingleStore Database and S3 Pipeline
Now that you have an S3 bucket that contains an object (file), you can use SingleStore or DB to create a new pipeline and ingest the messages.
Create a new database and a table that adheres to the schema contained in the books. file.
CREATE DATABASE books;
CREATE TABLE classic_books(title VARCHAR(255),author VARCHAR(255),date VARCHAR(255));
These statements create a new database named books and a new table named classic_, which has three columns: title, author, and date.
Now that the destination database and table have been created, you can create an S3 pipeline.books. file to your bucket.
-
The name of the bucket, such as:
<bucket-name> -
The name of the bucket’s region, such as:
us-west-1 -
Your AWS account’s access keys, such as:
-
Access Key ID:
<aws_access_ key_ id> -
Secret Access Key:
<aws_secret_ access_ key>
-
-
Your AWS account's session token, such as:
-
Session Token:
your_session_ token -
Note that the
aws_is required only if your credentials in thesession_ token CREDENTIALSclause are temporary
-
Using these identifiers and keys, execute the following statement, replacing the placeholder values with your own.
CREATE PIPELINE libraryAS LOAD DATA S3 'my-bucket-name'CONFIG '{"region": "us-west-1"}'CREDENTIALS '{"aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_secret_access_key", "aws_session_token": "your_session_token"}'INTO TABLE `classic_books`FIELDS TERMINATED BY ',';
You can see what files the pipeline wants to load by running the following:
SELECT * FROM information_schema.PIPELINES_FILES;
If everything is properly configured, you should see one row in the Unloaded state, corresponding to books..CREATE PIPELINE statement creates a new pipeline named library, but the pipeline has not yet been started, and no data has been loaded.
START PIPELINE library FOREGROUND;
When this command returns success, all files from your bucket will be loaded.information_ again, you should see all files in the Loaded state.classic_ table to make sure the data has actually loaded.
SELECT * FROM classic_books;
+------------------------+-----------------+-------+
| title | author | date |
+------------------------+-----------------+-------+
| The Catcher in the Rye | J.D. Salinger | 1945 |
| Pride and Prejudice | Jane Austen | 1813 |
| Of Mice and Men | John Steinbeck | 1937 |
| Frankenstein | Mary Shelley | 1818 |
+------------------------+-----------------+-------+You can also have SingleStore run your pipeline in the background.
DELETE FROM classic_books;ALTER PIPELINE library SET OFFSETS EARLIEST;
The first command deletes all rows from the target table.books. so you can load it again.
To start a pipeline in the background, run
START PIPELINE library;
This statement starts the pipeline.SHOW PIPELINES.
SHOW PIPELINES;
+----------------------+---------+
| Pipelines_in_books | State |
+----------------------+---------+
| library | Running |
+----------------------+---------+At this point, the pipeline is running and the contents of the books. file should once again be present in the classic_ table.
Note
Foreground pipelines and background pipelines have different intended uses and behave differently.
Scanning and Loading Files in AWS S3
S3 Pipelines discover new files by periodically rescanning the bucket.information_ and information_ views.
In the case of a large number of files, all the file names are stored in memory in metadata tables, such as information_ and information_.
-
File size must not be too small.
Smaller files also hurt the ingestion speed. -
Enable the OFFSETS METADATA GC clause when creating a pipeline.
This cleans up old filenames from the metadata table.
Note
Skipped files can be retried by pipelines by using the ALTER PIPELINE DROP FILE command.
Load Data Using pipeline_
Pipelines can extract, transform, and insert objects from an Amazon S3 bucket into a destination table.pipeline_.
Below is a list of three files that will be loaded into a table using an S3 pipeline.
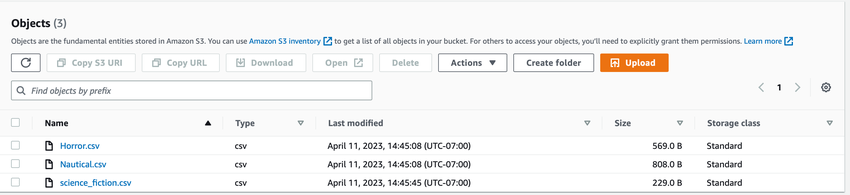
CREATE TABLE book_inventory(isbn NUMERIC(13),title VARCHAR(50));
Create an S3 pipeline to ingest the data.
CREATE PIPELINE books ASLOAD DATA S3 's3://<bucket_name>/Books/'CONFIG '{"region":"us-west-2"}'CREDENTIALS '{"aws_access_key_id": "<access_key_id>","aws_secret_access_key": "<secret_access_key>"}'SKIP DUPLICATE KEY ERRORSINTO TABLE book_inventory(isbn)SET title = pipeline_source_file();
Test the pipeline:
TEST PIPELINE books limit 5;
+---------------+------------------+
| isbn | title |
+---------------+------------------+
| 9780770437404 | Books/Horror.csv |
| 9780380977277 | Books/Horror.csv |
| 9780385319676 | Books/Horror.csv |
| 9781416552963 | Books/Horror.csv |
| 9780316362269 | Books/Horror.csv |
+---------------+------------------+Start the pipeline.
START PIPELINE books;
Check each row to verify that every one has a corresponding filename.
SELECT * FROM book_inventory;
+---------------+---------------------------+
| isbn | title |
+---------------+---------------------------+
| 9780316137492 | Books/Nautical.csv |
| 9780440117377 | Books/Horror.csv |
| 9780297866374 | Books/Nautical.csv |
| 9780006166269 | Books/Nautical.csv |
| 9780721405971 | Books/Nautical.csv |
| 9781416552963 | Books/Horror.csv |
| 9780316362269 | Books/Horror.csv |
| 9783104026886 | Books/Nautical.csv |
| 9788496957879 | Books/Nautical.csv |
| 9780380783601 | Books/Horror.csv |
| 9780380973835 | Books/science_fiction.csv |
| 9780739462287 | Books/science_fiction.csv |
+---------------+---------------------------+To load files from a specific folder in your S3 bucket while ignoring the files in the subfolders, use the '**' regular expression pattern as 's3://<bucket_'.
CREATE PIPELINE <your_pipeline> ASLOAD DATA S3 's3://<bucket_name>/<folder_name>/**'CONFIG '{"region":"<your_region>"}'CREDENTIALS '{"aws_access_key_id": "<access_key_id>","aws_secret_access_key": "<secret_access_key>"}'SKIP DUPLICATE KEY ERRORSINTO TABLE <your_table>;
Using two asterisks (**) after the folder instructs the pipeline to load all of the files in the main folder and ignore the files in the subfolders.
Next Steps
See About SingleStore Pipelines to learn more about how pipelines work.
In this section
Last modified: March 19, 2025