Parallelized Data Extraction with Pipelines
On this page
A pipeline extracts data from a source, in parallel, using these general rules:
-
The pipeline pairs n number of source partitions or objects with p number of SingleStore leaf node partitions.
-
Each leaf node partition runs its own extraction process independently of other leaf nodes and their partitions.
-
Extracted data is stored on the leaf node where a partition resides until it can be written to the destination table.
Depending on the way your table is sharded, the extracted data may only temporarily be stored on this leaf node.
Note
The term batch partition is used below and elsewhere in the documentation.
Data Loading for Azure Blob Pipelines
Similar to S3 pipelines, each leaf partition will process a single object from Azure Blob storage as part of a batch operation.
Data Loading for HDFS Pipelines
When the master aggregator reads an HDFS output directory’s contents, it schedules each file on a single SingleStore partition.
Data Loading for Kafka Pipelines
For Kafka pipelines to have optimal performance, there should be an equal number of partitions between SingleStore and Kafka (i.
In scenarios where the leaf nodes are processing unequal amounts of data, pipeline ingestion will generally outperform parallel loading through aggregator nodes.
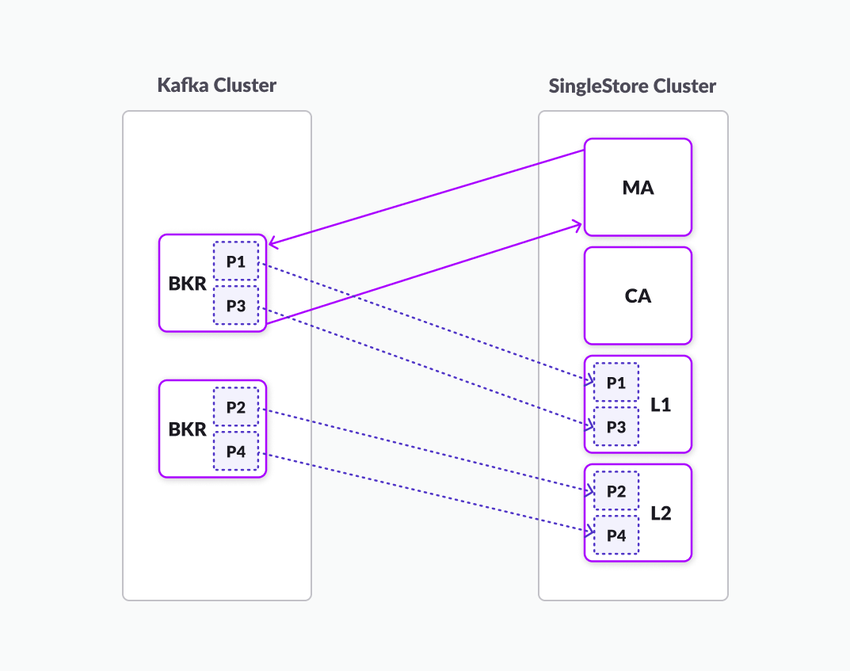
The SingleStore Master Aggregator (MA) connects to Kafka’s lead broker and requests metadata about the Kafka cluster, including information about the brokers, topics, and partitions.
Kafka to SingleStore One-to-One Relationship
|
Kafka Cluster |
SingleStore Cluster |
|
BKR (P1) (P3) |
MA = Master Aggregator |
|
|
CA = Child aggregator |
|
BKR (P2) (P4) |
L1 & L2 = Leaf 1 and Leaf 2 |
|
|
P1 - P4 = partitions 1 - 4 |
Data Loading for S3 Pipelines
For S3 pipelines, each leaf node partition will process a single object from the source bucket in a batch.
If the source bucket contains objects that greatly differ in size, it’s important to understand how an S3 pipeline’s performance may be affected.partition1 is processing an object that is 1KB in size, while partition2 is processing an object that is 10 MB in size.partition2.partition1 will sit idle and will not extract the next object from the bucket until partition2 finishes processing its 10 MB object.partition1 and partition2 are both finished processing their respective objects.
Last modified: February 23, 2024