Working with Vector Data
On this page
SingleStore supports vector database processing, which allows you to store and search vector data.
Some benefits of using SingleStore for vector database processing, as opposed to a specialized vector database system, are:
-
A broad array of standard modern database capabilities are available in SingleStore.
These include SQL, fast distributed and parallel query processing, full-text search, extensibility, ACID transactions, high availability, disaster recovery, point-in-time recovery, broad connectivity support, etc. -
Less data movement is needed between different data subsystems (e.
g. , caches, text search systems, SQL databases, and specialized vector databases) when all the data, including vector data, is stored in SingleStore. -
Operational costs may be reduced since fewer data management tools and fewer copies of the data are needed.
-
Less specialized skills and reduced labor may be needed to run an application environment.
Vector Data
Vector data consists of arrays of numbers.
Many large language models (LLMs) are now available, and can be used to provide vector embeddings for language to help implement semantic search, chatbots, and other applications.
-
GPT models from OpenAI
-
BERT by Google
-
LaMDA by Google
-
PaLM by Google
-
LLaMA by Meta AI
LLM technology is evolving quickly, and new sources of embeddings for language are rapidly becoming available.
Vector embeddings can be stored as vector data in SingleStore.
Vector Similarity Search
A similarity search is the most common vector data operation.SELECT…ORDER BY…LIMIT… queries that use vector similarity functions, including DOT_DOT_ is the most commonly used similarity metric.
If the vectors are normalized to length one before saving to a database, and the query vector is also normalized to length one, then DOT_ gives the cosine of the angle between the two vectors.DOT_ will produce what is known as the cosine similarity metric for its two arguments.
The figure below illustrates when vectors are similar (cosine close to 1) and dissimilar (cosine close to 0):
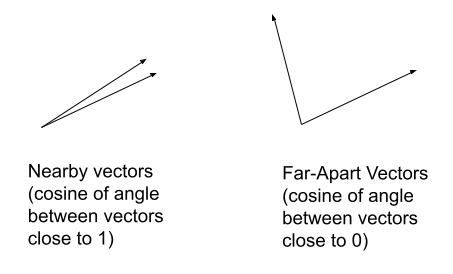
Note
When using high-dimensional vectors the cosine similarity concept is still applicable.
Many vector models that produce vector embeddings will already have the vectors normalized to length one.DOT_, it is not necessary to normalize the vectors again.
The EUCLIDEAN_ function calculates the Euclidean distance between two vectors.EUCLIDEAN_ range from 0 to infinity; values closer to 0 indicate that the vectors are similar, values closer to infinity indicate that vectors are less similar.
Loading, Inserting, and Updating Vectors
Vector data can be added to a database as blob data containing packed arrays of numbers.
CREATE TABLE comments_b(id INT,comment TEXT,vect BLOB,category VARCHAR(256));
Consider the following information where @jv is a JSON array of numbers representing the vector embedding for the phrase "The cafeteria in building 35 has a great salad bar.
SET @_id = 1;SET @cmt = "The cafeteria in building 35 has a great salad bar";SET @jv = '[0.45, 0.55, 0.495, 0.5]';SET @cat = "Food";
This data can be inserted into the comments table with a standard INSERT statement:
This data can be inserted into the comments table with a standard INSERT, using JSON_:
INSERT INTO comments_b VALUES (@_id, @cmt, JSON_ARRAY_PACK(@jv), @cat);
It is important to convert vectors into an internal binary vector format before inserting them into a database.JSON_ in the INSERT statement.
Binary data may be inserted in hexadecimal string format and converted using UNHEX before inserting it in a table.
UNHEX can be used to convert a hex string that will work for insert into the database.
SET @_id = 2;SET @cmt = "I love the taco bar in the B16 cafeteria.";SET @hs = "B806363CE90A363CCDCCCC3D77BE7F3F";SET @cat = "Food";
INSERT INTO comments_b VALUES (@_id, @cmt, unhex(@hs), @cat);
Insert a third tuple into this table.
SET @_id = 3;SET @cmt = "The B24 restaurant salad bar is quite good.";SET @jv = '[0.1, 0.8, 0.2, 0.555]';SET @cat = "Food";
INSERT INTO comments_b VALUES (@_id, @cmt, JSON_ARRAY_PACK(@jv), @cat);
View the contents of the table using this query.
SELECT id, comment, JSON_ARRAY_UNPACK(vect), categoryFROM comments_bORDER BY id;
*** 1. row ***
id: 1
comment: The cafeteria in building 35 has a great salad bar
JSON_ARRAY_UNPACK(vect): [0.449999988,0.550000012,0.495000005,0.5]
category: Food
*** 2. row ***
id: 2
comment: I love the taco bar in the B16 cafeteria.
JSON_ARRAY_UNPACK(vect): [0.0111100003,0.0111109996,0.100000001,0.999000013]
category: Food
*** 3. row ***
id: 3
comment: The B24 restaurant salad bar is quite good.
JSON_ARRAY_UNPACK(vect): [0.100000001,0.800000012,0.200000003,0.555000007]
category: FoodIf you are using a command line tool, you can use \G at the end of the query to get the results formatted as above.
Another way to insert binary vectors is to convert them to a packed binary format in the client application and submit them through a standard client API.
An alternate way to insert vector data is using pipelines.HEX or convert the vector data to binary before inserting.
Example Search Based on Vector Similarity
To find the most similar vectors in a query vector, use an ORDER BY… LIMIT… query.ORDER BY will arrange the vectors by their similarity score produced by a vector similarity function, with the closest matches at the top.
Suppose that the query is "restaurants with good salad," and for this query, the vector embedding API returned the vector '[0.
SET @query_vec = JSON_ARRAY_PACK('[0.44, 0.554, 0.34, 0.62]');SELECT id, comment, category, DOT_PRODUCT(vect, @query_vec) AS scoreFROM comments_bORDER BY score DESCLIMIT 2;
*** 1. row ***
id: 1
comment: The cafeteria in building 35 has a great salad bar
category: Food
score: 0.9810000061988831
*** 2. row ***
id: 3
comment: The B24 restaurant salad bar is quite good.
category: Food
score: 0.8993000388145447 -
Search queries must use the same metric used in the creation of a vector index in order to use that index.
That is, a query that uses DOT_can only use a vector index created withPRODUCT DOT_.PRODUCT -
Vectors must be normalized to length 1 before using the
DOT_function to obtain the cosine similarity metric.PRODUCT SingleStore recommends vectors be normalized to length 1 before they are saved to the database. Many models that produce vector embeddings produce vectors normalized to length one. In this case, it is not necessary to normalize the vectors again. -
Using
EUCLIDEAN_over vectors which have been normalized to length 1 may result in poor recall.DISTANCE
Hybrid Filtering or Metadata Filtering
When building vector search applications, you may wish to filter on the fields of a record, with simple filters or via joins, in addition to applying vector similarity operations.
For example, given the comments table, you can get the top three matches for a query vector that is in the category "Food" using this SQL:
SET @query_vec = JSON_ARRAY_PACK('[ a query vector from your application ]');SELECT id, comment, category, DOT_PRODUCT(vect, @query_vec) AS scoreFROM comments_bWHERE category = "Food"ORDER BY score DESCLIMIT 3;
Any SQL feature can be used along with vector similarity calculation using DOT_ and EUCLIDEAN_.
Hybrid Search
Hybrid searching uses a combination of vector similarity search and full-text search.
This command adds a full-text index on the comment field:
ALTER TABLE comments_b ADD FULLTEXT(comment);
Run the following command to ensure the values above are indexed.
OPTIMIZE TABLE comments_b FLUSH;
The commands below first create a query vector and then combines the full-text and DOT_ similarity scores for the query with equal weight and returns the top two matches.
The row with id 3 has the word "restaurant" in it, so it gets a boost from the full-text search here and is delivered at the top of the ranking.
SET @query_vec = JSON_ARRAY_PACK('[0.44, 0.554, 0.34, 0.62]');SELECT id, comment, DOT_PRODUCT(@query_vec, vect) AS vec_score,MATCH(comment) AGAINST ("restaurant") AS ft_score,(vec_score + ft_score) / 2 AS combined_scoreFROM comments_bORDER BY combined_score DESCLIMIT 2;
*** 1. row ***
id: 3
comment: The B24 restaurant salad bar is quite good.
vec_score: 0.8993000388145447
ft_score: 0.11506980657577515
combined_score: 0.5071849226951599
*** 2. row ***
id: 1
comment: The cafeteria in building 35 has a great salad bar
vec_score: 0.9810000061988831
ft_score: 0
combined_score: 0.49050000309944153To use the full-text search index to limit the search to just rows with specific keywords, add a WHERE clause with a MATCH…AGAINST… expression.
SET @query_vec = JSON_ARRAY_PACK('[0.44, 0.554, 0.34, 0.62]');SELECT id, comment, DOT_PRODUCT(@query_vec, vect) AS vec_score,MATCH(comment) AGAINST ("restaurant") AS ft_score,(vec_score + ft_score) / 2 AS combined_scoreFROM comments_bWHERE MATCH(comment) AGAINST ("restaurant")ORDER BY combined_score DESCLIMIT 2;
*** 1. row ***
id: 3
comment: The B24 restaurant salad bar is quite good.
vec_score: 0.8993000388145447
ft_score: 0.11506980657577515
combined_score: 0.5071849226951599The WHERE clause, in this case, limits the search to rows with "restaurant" in the comment column.
The availability of vector search, full-text search, and standard SQL operations in SingleStore allows you to combine them to identify important data in powerful ways.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a method for enhancing the quality of results for text-based Generative AI (GenAI) applications.
In advance:
-
split up relevant text into chunks
-
get a vector for each chunk from your chosen LLM and place the chunks in SingleStore
Then, when a question comes in for which you wish to generate an answer:
-
get a vector for the question from the same LLM
-
search the stored vectors to find the top k matching vectors compared with the query vector
-
for each of these top vectors, get the associated text chunks
-
pass these chunks to the LLM’s question-answering API as context, along with the original question
This method helps the LLM generate high-quality results for a specialized topic, beyond what it was trained for.
Tools such as Langchain, or a Natural Language Processing (NLP) library like spaCy or NLTK can be used to make splitting documents into chunks take less time for the application developer.
How to Bulk Load Vectors
Vector data can be inserted into SingleStore from your application by using standard INSERT statements.
Use this format for the table:
CREATE TABLE vec_test(id INT, vec blob, shard(id));
Use a text file formatted using tabs (or some other character besides commas) between the columns./tmp/vec_ in the examples below):
1 [0.18,0.36,0.54,0.73]
2 [0.62,0.70,0.15,0.31]Loading Data Using a Local File
LOAD DATA infile '/tmp/vec_data.txt'INTO TABLE vec_testfields terminated by ' '(id, @vec_text)SET vec = JSON_ARRAY_PACK(@vec_text);
Using JSON_
Validate the data in the table using the following SQL.
SELECT id, JSON_ARRAY_UNPACK(vec)FROM vec_test;
+------+---------------------------------------------------+
| id | JSON_ARRAY_UNPACK(vec) |
+------+---------------------------------------------------+
| 1 | [0.180000007,0.360000014,0.540000021,0.730000019] |
| 2 | [0.620000005,0.699999988,0.150000006,0.310000002] |
+------+---------------------------------------------------+The rounding errors compared with the input file are normal due to the inexact nature of floating-point conversions from decimal strings.
Loading Large Datasets
To load a large dataset or continuous streaming data use a pipeline.
TRUNCATE TABLE vec_test;
Create and start the pipeline:
CREATE PIPELINE vec_pipeline ASLOAD DATA fs '/tmp/vec_data.txt'INTO TABLE vec_test fields terminated BY ' '(id, @vec_text)SET vec = JSON_ARRAY_PACK(@vec_text);
START PIPELINE vec_pipeline;
Validate the vector data using:
SELECT id, JSON_ARRAY_UNPACK(vec)FROM vec_test;
+------+---------------------------------------------------+
| id | JSON_ARRAY_UNPACK(vec) |
+------+---------------------------------------------------+
| 1 | [0.180000007,0.360000014,0.540000021,0.730000019] |
| 2 | [0.620000005,0.699999988,0.150000006,0.310000002] |
+------+---------------------------------------------------+Stop or drop the pipeline when it is no longer needed.
STOP PIPELINE vec_pipeline;DROP PIPELINE vec_pipeline;
If using SingleStore Helios, store your data in a cloud object store.
Related Topics
Last modified: April 24, 2025