Parallel Read Support
You can enable parallel reads via the enableParallelRead option.
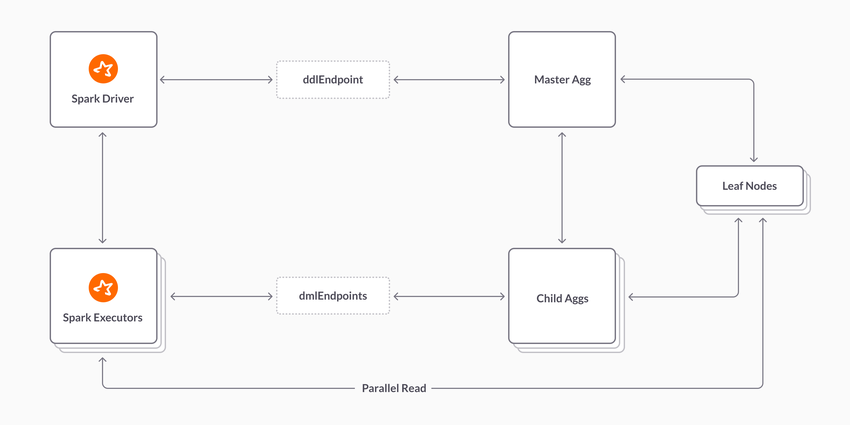
Note: Parallel reads are not consistent
Parallel reads read directly from partitions on the leaf nodes, which skips our transaction layer.
Note: Parallel reads transparently fallback to single stream reads
Parallel reads currently only work for query-shapes which do not work on the Aggregator and thus can be pushed entirely down to the leaf nodes.
df.rdd.getNumPartitions
If this value is > 1 then we are reading in parallel from leaf nodes.
Note: Parallel reads require consistent authentication and connectible leaf nodes
In order to use parallel reads, the username and password provided to the singlestore-spark-connector must be the same across all nodes in the cluster.
In addition, the hostnames and ports listed by SHOW LEAVES must be directly connectible from Spark.
Last modified: February 23, 2024