Load Data from AWS Glue
On this page
AWS Glue is a fully managed serverless data integration service that allows users to extract, transform, and load (ETL) from various data sources for analytics and data processing.
SingleStore provides a SingleStore connector for AWS Glue based on Apache Spark Datasource, available through AWS Marketplace.
This topic shows how you can use SingleStore’s AWS Glue Marketplace Connector in AWS Glue Studio to create ETL jobs connecting to your SingleStore cluster using an easy-to-use graphical interface.
The following architecture diagram shows SingleStore connecting with AWS Glue for an ETL job.
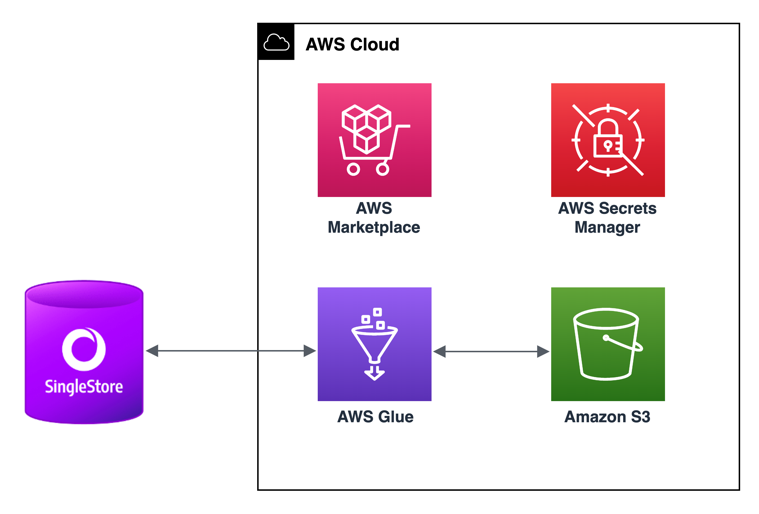
The SingleStore connector for AWS Glue is compatible with SingleStore versions 7.
Prerequisites
The SingleStore AWS Glue connector is only compatible with AWS Glue version 3.
You must have admin access to the AWS account.
The SingleStore AWS Glue connector returns an error if you use the following regions in AWS: Hong Kong, Sao Paolo, Stockholm, Bahrain, and Cape Town.
Create a SingleStore cluster and load TPC-H dataset.
Configuration Overview
The following steps connect a SingleStore cluster in an AWS Glue ETL job as the source, transform the data, and store it back on a SingleStore cluster and in Apache Parquet format on Amazon S3.
To successfully create the ETL job using the SingleStore connector:
-
Store authentication credentials in Secrets Manager.
-
Create an AWS Identity and Access Management (IAM) role for the AWS Glue ETL job.
-
Configure the SingleStore connector and connection.
-
Create an ETL job using the SingleStore connection in AWS Glue Studio.
Store Authentication Credentials in Secrets Manager
AWS Glue provides integration with AWS Secrets Manager to securely store connection authentication credentials.
-
Log in to AWS, and select AWS Management Console > AWS services > Secrets Manager.
-
In the Secrets dialog, select Store a new secret.
-
Under Secret type, select Other type of secrets.
-
In the Store a new secret dialog, under Key/value pairs, set one row for each of the following parameters:
-
ddlEndpoint -
database -
user -
password

Select Next.
-
-
In the Secret name box, enter
aws-glue-singlestore-connection-info.Select Next. -
Enable Disable automatic rotation, and then select the Next button.
-
Select Store.
Open the secret from the list. Copy the Secret ARN, and store it at a secure location.
Create an IAM Role for the AWS Glue ETL Job
To create a role with an attached policy to allow read-only access to credentials that are stored in Secrets Manager for the AWS Glue ETL job:
-
Log in to AWS, and select AWS Management Console > AWS services > IAM.
-
In the IAM dialog, select Policies > Create Policy.
-
On the JSON tab, enter the following JSON snippet (update the Region and account ID from the Secret ARN):
{"Version": "2012-10-17","Statement": [{"Sid": "VisualEditor0","Effect": "Allow","Action": ["secretsmanager:GetSecretValue","secretsmanager:DescribeSecret"],"Resource": "arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:aws-glue-*"}]} -
Select Next.
-
Enter a name for the policy, for example, GlueAccessSecretValue.
-
In the navigation pane, select Roles > Create role.
-
In the Create Role dialog, under Select type of trusted entity, select AWS Service.
Under Choose a use case, select Glue. -
Select Next.
-
Find and select the following AWS managed policies:
AWSGlueServiceRoleandAmazonEC2ContainerRegistryReadOnly. -
Find the policy created earlier
GlueAccessSecretValue, and select it. -
In the Role name box, enter a role name (for example, GlueCustomETLConnectionRole).
-
Confirm that the three policies are selected, and select Create role.

Configure the SingleStore Connector and Connection
To subscribe to the SingleStore connector and configure the connection:
-
On the dashboard, select AWS Glue > AWS Glue Studio.
-
In the Getting Started dialog, select View connectors.

-
Select Go to AWS Marketplace.
On the AWS Marketplace, subscribe to the latest version of the SingleStore connector for AWS Glue. Select Continue to Subscribe. -
Once the subscription request is successful, select Continue to Configuration.
-
On the Configure this software page, from the Software version list, select the latest version of the connector, and select Continue to Launch.
-
On the Launch this software page, select Usage instructions.
-
On the Usage Instructions dialog, open the Activate the Glue connector using AWS Glue Studio link to activate the connector.
-
In AWS Glue Studio, select Connectors > Create connection.
-
In the Create connection dialog, under Connection properties, enter a name for the connection in the Name box, for example
SingleStore_.connection -
From the AWS Secret list, select the AWS secret value
aws-glue-singlestore-connection-infocreated earlier. -
Select Create connection and activate connector.
Create an ETL Job using the SingleStore Connection in AWS Glue Studio
After you have set up authentication and configured the SingleStore connector, to create an ETL job using the connection:
-
In AWS Glue Studio, select Connectors.
-
In the Connections dialog, select SingleStore_
connection (the connection created earlier). Select Create job. -
On the Job details tab, in the Name box, enter a name for the job, for example SingleStore_
tpch_ transform_ job. -
In the Description box, enter a description, for example Glue job to transform tpch data from SingleStore.
-
From the IAM Role list, select GlueCustomETLConnectionRole.
-
From the Glue version list, select Glue 3.
0. -
Use default settings for other properties.
Select Save. -
On the Visual tab, in the workspace area, select the SingleStore Data source - Connection.
On the Data source properties – Connector tab, expand Connection options, and select Add new option. 
-
Under Connection options, in the Key box, enter dbtable.
(In this example, we will use the lineitemtable from thetpchdatabase.) In the Value box, enter lineitem. -
On the Output schema tab, select Edit.
Select the three dots, and select Add root key from the list. Note
In this example, AWS Glue Studio is using information stored in the connection to access the data source instead of retrieving metadata information from a Data Catalog table.
Hence, you must provide the schema metadata for the data source. Use the schema editor to update the source schema. For instructions on how to use the schema editor, refer to Editing the schema in a custom transform node. -
Add the key and data type, which represent the name of the column in the database and its data type, respectively.
Select Apply. -
On the Visual tab workspace area, select Add nodes, and then select DropFields from the list.
-
On the Transform tab (for Drop Fields), from the Node parents list, select SingleStore connector for AWS Glue.
-
Select the fields to drop.
-
On the Visual tab workspace area, select Add node, and then select Custom Transform from the list.
-
From the Node parents list, select Drop Fields.
-
Add the following script to the Code block box:
def MyTransform (glueContext, dfc) -> DynamicFrameCollection:from pyspark.sql.functions import coldf = dfc.select(list(dfc.keys())[0]).toDF().limit(100)df1 = df.withColumn("disc_price",(col("l_extendedprice")*(1-col("l_discount"))).cast("decimal(10,2)"))df2 = df1.withColumn("price", (col("disc_price")*(1+col("l_tax"))).cast("decimal(10,2)"))dyf = DynamicFrame.fromDF(df2, glueContext, "updated_lineitem")glueContext.write_dynamic_frame.from_options(frame = dyf,connection_type = "marketplace.spark",connection_options = {"dbtable":"updated_lineitem","connectionName":"SingleStore_connection"})return(DynamicFrameCollection({"CustomTransform0": dyf}, glueContext))In this example, we calculate two additional columns,
disc_andprice price.Then we use glueContext.to write the updated data back on SingleStore using the connection SingleStore_write_ dynamic_ frame connection created earlier. Note
You can specify any of the configuration settings in
connection_.options For example, the following statement (from the script above) is extended to specify a shard key: glueContext.write_dynamic_frame.from_options(frame = dyf, connection_type = "marketplace.spark", connection_options = {"dbtable":"updated_lineitem","connectionName":"SingleStore_connection", "tableKey.shard" : "l_partkey"}) -
On the Output schema tab, select Edit.
Add the additional columns priceanddisc_with theprice decimaldata type.Select Apply. -
On the Visual tab, in the workspace area, select Add nodes > Select from Collection.
-
On the Transform tab, from the Node parents list, select Custom transform.
-
Select Add nodes.
From the Target list, select Amazon S3. -
From the Node parents list, select Select from Collection.
-
On the Data target properties - S3 tab, from the Format list, select Parquet.
-
In the S3 Target Location box, enter
s3://aws-glue-assets-{Your Account ID as a 12-digit number}-{AWS region}/output/or select from the list.
-
Select Save > Run.
Last modified: May 30, 2024