Replicate MongoDB® Collections using SQL
On this page
Note
SingleStore does not recommend using this feature if you are using a SingleStore Kai-enabled workspace as it may create table structures that are not optimal for the API.
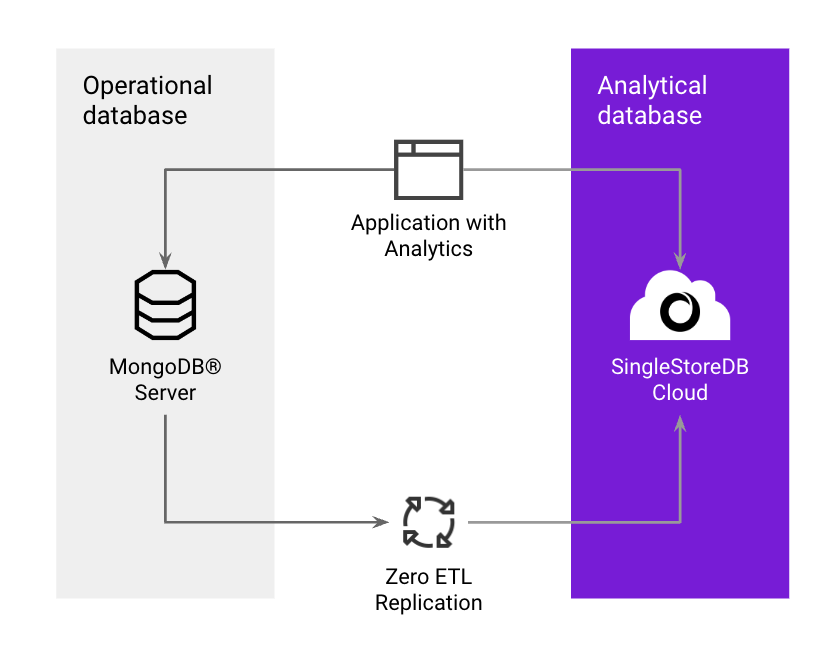
You can replicate your existing MongoDB® collections to your SingleStore Helios database using SQL commands via Change Data Capture (CDC) pipelines.
Note
You can only create a maximum of 16 CDC-in pipelines in total for MongoDB® and MySQL sources.
Perform the following tasks:
-
Ensure that the Prerequisites are met.
-
(Optional) Create a link to the MongoDB® instance.
Refer to CREATE LINK for more information. You can also specify the link configuration and credentials in the CONFIG/CREDENTIALSclause of theCREATE {TABLES | TABLE} AS INFER PIPELINESQL statement instead of creating a link. -
Create the required table(s), stored procedure(s), and pipeline(s) using the
CREATE {TABLES | TABLE} AS INFER PIPELINESQL statement.Refer to Syntax for more information. You can either replicate the MongoDB® collections as is or apply custom transformations. Note
Before restarting the
INFER PIPELINEoperation, delete all the related artifacts.DROP TABLE <target_table_name>;DROP PIPELINE <pipeline_name>;DROP PROCEDURE <procedure_name>; -
Once all the components are configured, start the pipelines.
-
To start all the pipelines, run the
START ALL PIPELINESSQL statement. -
To start a specific pipeline, run the
START PIPELINE <pipeline_SQL statement.name> By default, the pipeline is named <source_.db_ name>. <table_ name>
-
To ingest data in the JSON format instead of BSON, you need to manually create the required table structures, pipelines, and stored procedures for mapping the BSON data type to JSON.
For more information, refer to the relevant section on this page:
Replicate MongoDB® Collections Example
The following example shows how to replicate MongoDB® collections without any custom transformations.LINK clause to specify the MongoDB® Atlas endpoint connection configuration.
-
Create a link to the MongoDB® endpoint, for example, the primary node of a MongoDB® Atlas cluster.
CREATE LINK <linkname> AS MONGODBCONFIG '{"mongodb.hosts":"<Hostname>","collection.include.list": "<Collection list>","mongodb.ssl.enabled":"true","mongodb.authsource":"admin"}'CREDENTIALS '{"mongodb.user":"<username>","mongodb.password":"<password>"}'; -
Create tables, pipelines, and stored procedures in SingleStore Helios based on the inference from the source collections.
CREATE TABLES AS INFER PIPELINE AS LOAD DATALINK <linkname> '*' FORMAT AVRO; -
Once the link and the tables are created, run the following command to start all the pipelines and begin the data replication process:
## Start pipelinesSTART ALL PIPELINES; -
To view the ingested BSON data, SingleStore recommends the following:
-
Use the Kai Shell or other supported MongoDB® tools, such as MongoDB® Compass.
-
Cast the columns to JSON using the following SQL command:
SELECT _id :> JSON , _more :> JSON FROM <table_name>;
-
The following notebook demonstrates how to ingest data from MongoDB® using SQL commands:
Ingest data from MONGODB® to SingleStore using SQL commands
 |
When do you use SingleStore's native replication capability from MongoDB ?
SingleStore's native data replication gives you the ability to do one-time snapshot, or continuous change data capture CDC from MongoDB® to SingleStoreDB. This provides a quick and easy way to replicate data and power up analytics on MongoDB® data.
What you will learn in this notebook:
Replicate MongoDB® collections to SingleStore
- Directly without transformations
- Flattening required fields into columns of a table
- Normalizing collection into multiple tables
1. Replicate directly without transformations
To replicate the required collections, provide the list of collections using "collection.include.list": "<Collection list>" at the time of link creation, the parameter takes a comma-separated list of regular expressions that match collection names (in databaseName.collectionName format)
%%sqlDROP DATABASE IF EXISTS sample_analytics;CREATE DATABASE sample_analytics;
Action Required
Make sure to select a database from the drop-down menu at the top of this notebook. It updates the connection_url to connect to that database.
%%sqlCREATE LINK cdclink AS MONGODBCONFIG '{"mongodb.hosts":"ac-t7n47to-shard-00-00.tfutgo0.mongodb.net:27017,ac-t7n47to-shard-00-01.tfutgo0.mongodb.net:27017,ac-t7n47to-shard-00-02.tfutgo0.mongodb.net:27017","collection.include.list": "sample_analytics.customers","mongodb.ssl.enabled":"true","mongodb.authsource":"admin","mongodb.members.auto.discover": "true"}'CREDENTIALS '{"mongodb.user":"mongo_sample_reader","mongodb.password":"SingleStoreRocks27017"}'
Check if the link got created
%%sqlSHOW LINKS;
The following step automatically creates the required tables and pipelines on SingleStoreDB for every collection configured for replication
%%sqlCREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK cdclink '*' FORMAT AVRO;
Start pipelines to begin replicating the data
%%sqlSTART ALL PIPELINES;
%%sqlSHOW TABLES;
The customer collection from MongoDB are replicated into SingleStore in the default format of _id and _more BSON columns that are compatible with Kai API
%%sqlSELECT (_id :> JSON),(_more :> JSON) FROM customers LIMIT 2;
2. Flattening required fields from document into columns
CDC replication also gives additional flexibility to define your own table structure at SingleStore as you bring in data from MongoDB collections. In the following examples data from MongoDB collections are transformed when brought to SingleStoreDB
Fields like username, name, email are flattened into columns of the table and rest of the document is stored in _more column.
The following commands create a table, a stored procedure and a pipeline required for the data replication
%%sqlCREATE TABLE `customers_flattened` (`_id` bson NOT NULL,`username` text CHARACTER SET utf8 COLLATE utf8_general_ci,`name` text CHARACTER SET utf8 COLLATE utf8_general_ci,`email` text CHARACTER SET utf8 COLLATE utf8_general_ci,`_more` bson NOT NULL COMMENT 'KAI_MORE' ,`$_id` as BSON_NORMALIZE_NO_ARRAY(`_id`) PERSISTED longblob COMMENT 'KAI_AUTO' ,SHARD KEY `__SHARDKEY` (`$_id`),UNIQUE KEY `__PRIMARY` (`$_id`) USING HASH,SORT KEY `__UNORDERED` ())
%%sqlCREATE OR REPLACE PROCEDURE `customers_apply_changes`(changes query(`__operation` int(11) NOT NULL, `_id` longblob NOT NULL, `_more` longblob NOT NULL))RETURNS void ASDECLARE rowsDeleted INT;BEGIN REPLACE INTO `sample_analytics`.`customers_flattened` SELECT `_id`:>BSON AS `_id`, BSON_EXTRACT_STRING(`_more`,'username') AS `username`, BSON_EXTRACT_STRING(`_more`,'name') AS `name`, BSON_EXTRACT_STRING(`_more`,'email') AS `email`,BSON_EXCLUDE_MASK(`_more`,'{"_id": 1,"username": 1,"name": 1,"email": 1}') AS `_more`FROM changes WHERE __operation != 1;SELECT count(*) INTO rowsDeleted FROM changes WHERE changes.__operation = 1;IF rowsDeleted > 0 THENDELETE dest FROM `sample_analytics`.`customers_flattened` AS dest INNER JOIN changes ON dest.`$_id` = BSON_NORMALIZE_NO_ARRAY(changes.`_id`) WHERE changes.__operation = 1; END IF;END;
%%sqlCREATE AGGREGATOR PIPELINE `customers_apply_changes`AS LOAD DATA LINK cdclink 'customers'BATCH_INTERVAL 2500MAX_PARTITIONS_PER_BATCH 1DISABLE OFFSETS METADATA GCREPLACEKEY(`_id`)INTO PROCEDURE `customers_apply_changes`FORMAT AVRO(__operation <- `__operation`,_id <- `payload`::`_id`,_more <- `payload`::`_more`)
%%sqlSTART ALL PIPELINES;
%%sqlSHOW TABLES;
%%sqlSELECT _id :> JSON,username, name, email, _more :> JSON FROM customers_flattened LIMIT 10;
3. Normalize a collection into multiple tables
In the following example a collection of MongoDB is normalized into two different tables on SingleStore.
%%sqlDROP DATABASE IF EXISTS sample_airbnb;CREATE DATABASE sample_airbnb;
Action Required
Make sure to select a database from the drop-down menu at the top of this notebook. It updates the connection_url to connect to that database.
%%sqlCREATE LINK source_listingsAndReviews AS MONGODBCONFIG '{"mongodb.hosts":"ac-t7n47to-shard-00-00.tfutgo0.mongodb.net:27017,ac-t7n47to-shard-00-01.tfutgo0.mongodb.net:27017,ac-t7n47to-shard-00-02.tfutgo0.mongodb.net:27017","collection.include.list": "sample_airbnb.*","mongodb.ssl.enabled":"true","mongodb.authsource":"admin","mongodb.members.auto.discover": "true"}'CREDENTIALS '{"mongodb.user":"mongo_sample_reader","mongodb.password":"SingleStoreRocks27017"}'
%%sqlSHOW LINKS;
%%sqlCREATE TABLE `listings` (`_id` BSON NOT NULL,`name` text CHARACTER SET utf8 COLLATE utf8_general_ci,`access` text CHARACTER SET utf8 COLLATE utf8_general_ci,`accommodates` int(11) DEFAULT NULL,`_more` BSON NOT NULL,`$_id` as BSON_NORMALIZE_NO_ARRAY(`_id`) PERSISTED longblob,SHARD KEY `__SHARDKEY` (`$_id`),UNIQUE KEY `__PRIMARY` (`$_id`) USING HASH,SORT KEY `__UNORDERED` ())
%%sqlCREATE TABLE `reviews` (`listingid` BSON NOT NULL,`review_scores_accuracy` int(11) DEFAULT NULL,`review_scores_cleanliness` int(11) DEFAULT NULL,`review_scores_rating` text CHARACTER SET utf8 COLLATE utf8_general_ci,`$listingid` as BSON_NORMALIZE_NO_ARRAY(`listingid`) PERSISTED longblob,SHARD KEY `__SHARDKEY` (`$listingid`),UNIQUE KEY `__PRIMARY` (`$listingid`) USING HASH,SORT KEY `__UNORDERED` ())
%%sqlCREATE OR REPLACE PROCEDURE `listingsAndReviews_apply_changes`(changes query(`__operation` int(11) NOT NULL, `_id` longblob NOT NULL, `_more` longblob NOT NULL))RETURNS void ASDECLARE rowsDeleted INT;BEGINREPLACE INTO `listings` SELECT `_id`:>BSON AS `_id`, BSON_EXTRACT_STRING(`_more`,'name') AS `name`, BSON_EXTRACT_STRING(`_more`,'access') AS `access`,BSON_EXTRACT_BIGINT(`_more`,'accommodates') AS `accommodates`, BSON_EXCLUDE_MASK(`_more`,'{"_id": 1,"name": 1,"review_scores": 1,"access" : 1, "accommodates" : 1}') AS `_more`FROM changes WHERE __operation != 1;REPLACE INTO `reviews` SELECT `_id`:>BSON AS `listingid`, BSON_EXTRACT_BIGINT(`_more`,'review_scores','review_scores_accuracy') AS `review_scores_accuracy`,BSON_EXTRACT_BIGINT(`_more`,'review_scores','review_scores_cleanliness') AS `review_scores_cleanliness`, BSON_EXTRACT_BIGINT(`_more`,'review_scores','review_scores_rating') AS `review_scores_rating`FROM changes WHERE __operation != 1;SELECT count(*) INTO rowsDeleted FROM changes WHERE changes.__operation = 1;IF rowsDeleted > 0 THENDELETE dest FROM `listings` AS dest INNER JOIN changes ON dest.`$_id` = BSON_NORMALIZE_NO_ARRAY(changes.`_id`) WHERE changes.__operation = 1;DELETE dest FROM `reviews` AS dest INNER JOIN changes ON dest.`$listingid` = BSON_NORMALIZE_NO_ARRAY(changes.`_id`) WHERE changes.__operation = 1;END IF;END;
%%sqlCREATE AGGREGATOR PIPELINE `listingsAndReviews`AS LOAD DATA LINK source_listingsAndReviews 'sample_airbnb.listingsAndReviews'BATCH_INTERVAL 2500MAX_PARTITIONS_PER_BATCH 1DISABLE OFFSETS METADATA GCREPLACEKEY(`_id`)INTO PROCEDURE `listingsAndReviews_apply_changes`FORMAT AVRO(__operation <- `__operation`,_id <- `payload`::`_id`,_more <- `payload`::`_more`)
%%sqlSTART ALL PIPELINES;
%%sqlSHOW TABLES;
%%sqlSELECT _id:>JSON ,name, access, accommodates FROM listings LIMIT 10;
%%sqlSELECT listingid:>JSON, review_scores_accuracy,review_scores_cleanliness, review_scores_rating FROM reviews LIMIT 10;
Syntax
CREATE TABLE [IF NOT EXISTS] <table_name>AS INFER PIPELINEAS LOAD DATA <mongodb_configuration>FORMAT AVRO;-- Use either the LINK or MONGODB clause, they are mutually exclusive --<mongodb_configuration>:LINK <link_name> "<source_db>.<source_collection>"| MONGODB "<source_db>.<source_collection>" CONFIG <config_json> CREDENTIALS <credentials_json>
CREATE TABLES [IF NOT EXISTS]AS INFER PIPELINEAS LOAD DATA <mongodb_configuration>FORMAT AVRO;-- Use either the LINK or MONGODB clause, they are mutually exclusive --<mongodb_configuration>:LINK <link_name> "*"| MONGODB '*' CONFIG <config_json> CREDENTIALS <credentials_json>
CREATE TABLE . Behavior
The CREATE TABLE [IF NOT EXISTS] <table_ statement,
-
Connects to the MongoDB® servers using the specified
LINK <link_orname> MONGODB <collection> CONFIG <conf_clause.json> CREDENTIALS <cred_ json> -
Discovers the available databases and collections filtered by
collection..include. list -
Infers the schema of the collection and then creates a table (named <table_
name>) in SingleStore using the inferred schema. You can also specify a table name that differs from the name of the source MongoDB® collection. If the specified table already exists, a new table is not created and the existing table is used instead. -
Creates a pipeline (named <source_
db_ name>. <table_ name>) and stored procedure (named <source_ db_ name>. <table_ name>) that maps the AVRO data structure to the SingleStore data structure. The [IF NOT EXISTS]clause is ignored for pipelines and stored procedures.If a pipeline or stored procedure with the same name already exists, the CREATE TABLE .statement returns an error.. . AS INFER PIPELINE
CREATE TABLES AS INFER PIPELINE Behavior
The CREATE TABLES [IF NOT EXISTS] AS INFER PIPELINE statement creates a table for each collection in the source database using the same set of operations as the CREATE TABLE [IF NOT EXISTS] <table_ statement (specified above).
Arguments
-
<table_: Name of the table to create in the SingleStore Helios database.name> You can also specify a table name that differs from the name of the source MongoDB® collection. -
<link_: Name of the link to the MongoDB® endpoint.name> Refer to CREATE LINK for more information. -
<collection>: Name of the source MongoDB® collection. -
<config_: Configuration parameters, including the source MongoDB® configuration, in the JSON format.json> Refer to Parameters for supported parameters. -
<credentials_: Credentials to use to access the MongoDB® database, in JSON format.json> For example: CREDENTIALS '{"mongodb.password": "<password>", "mongodb.user": "<user>"}'-
mongodb.: The name of the database user to use when connecting to MongoDB® servers.user -
mongodb.: The password to use when connecting to MongoDB® servers.password
-
Parameters
The CREATE {TABLE | TABLES}, CREATE LINK.CREATE AGGREGATOR PIPELINE statement supports the following parameters in the CONFIG clause:
-
mongodb.: A comma-separated list of MongoDB® servers (nodes) in the replica set, inhosts 'hostname:[port]'format.The
mongodb.andconnection. string mongodb.parameters are mutually exclusive, i.hosts e. , they cannot be used in the same CREATE TABLE .statement.. . AS INFER PIPELINE -
If
mongodb.is set tomembers. auto. discover FALSE, you must prefix the'hostname:[port]'with the name of the replica set inmongodb., e.hosts g. , rset0/svchost-xxx:27017. The first node specified in mongodb.is always selected as the primary node.hosts -
If
mongodb.is set tomembers. auto. discover TRUE, you must specify both the primary and secondary nodes in the replica set inmongodb..hosts
-
-
mongodb.: Specifies the URI of the remote MongoDB® instance.connection. string This parameter supports both the standard and SRV connection string formats. The mongodb.andconnection. string mongodb.parameters are mutually exclusive, i.hosts e. , they cannot be used in the same CREATE TABLE .statement.. . AS INFER PIPELINE -
mongodb.: Specifies whether the MongoDB® servers defined inmembers. auto. discover mongodb.should be used to discover all the members of the replica set.hosts If disabled, the servers are used as is. -
mongodb.: Enables the connector to use SSL when connecting to MongoDB® servers.ssl. enabled -
mongodb.: Specifies the database containing MongoDB® credentials to use as an authentication source.authsource This parameter is only required when the MongoDB® instance is configured to use authentication with an authentication database other than admin. -
mongodb.: Specifies the socket timeout (in milliseconds) for connections to a MongoDB® instance.socket. timeout. ms The pipeline returns an error if there is no response from the MongoDB® server within the specified timeout. By default, mongodb.is set tosocket. timeout. ms 12000(2 minutes).Note: SingleStore does not recommend updating this parameter unless troubleshooting unusual behavior.
-
collection.: A comma-separated list of regular expressions that match fully-qualified namespaces (ininclude. list databaseName.format) for MongoDB® collections to monitor.collectionName By default, all the collections are monitored, except for those in the localandadmindatabases.When this option is specified, collections excluded from the list are not monitored. The collection.andinclude. list collection.parameters are mutually exclusive, i.exclude. list e. , they cannot be used in the same CREATE TABLE .statement.. . AS INFER PIPELINE This parameter is only supported in CREATE TABLE .statements.. . AS INFER PIPELINE -
collection.: A comma-separated list of regular expressions that match fully-qualified namespaces (inexclude. list databaseName.format) for MongoDB® collections to exclude from the monitoring list.collectionName By default, this list is empty. The collection.andinclude. list collection.parameters are mutually exclusive, i.exclude. list e. , they cannot be used in the same CREATE TABLE .statement.. . AS INFER PIPELINE This parameter is only supported in CREATE TABLE .statements.. . AS INFER PIPELINE -
database.(Optional): A comma-separated list of regular expressions that match the names of databases to monitor.include. list By default, all the databases are monitored. When this option is specified, databases excluded from the list are not monitored. The database.andinclude. list database.parameters are mutually exclusive, i.exclude. list e. , they cannot be used in the same CREATE TABLE .statement.. . AS INFER PIPELINE If this option is used with the collection.orinclude. list collection.option, it returns the intersection of the matches.exclude. list This parameter is only supported in CREATE TABLE .statements.. . AS INFER PIPELINE -
database.(Optional): A comma-separated list of regular expressions that match the names of databases to exclude from monitoring.exclude. list By default, this list is empty. The database.andinclude. list database.parameters are mutually exclusive, i.exclude. list e. , they cannot be used in the same CREATE TABLE .statement.. . AS INFER PIPELINE If this option is used with the collection.orinclude. list collection.option, it returns the intersection of the matches.exclude'list This parameter is only supported in CREATE TABLE .statements.. . AS INFER PIPELINE -
signal.(Optional): A collection in the remote source that is used by SingleStore to generate special markings for snapshotting and synchronization.data. collection By default, this parameter is set to singlestore., wheresignals_ xxxxxx xxxxxxis an automatically generated character sequence.The default signal collection is in the database named singlestore.The MongoDB® user must have write permissions to this collection. Once the pipelines are started, any change to the value of this parameter is ignored, and the pipelines use the latest value specified before the pipelines started. -
max.: Specifies the size of the queue inside the extractor process for records that are ready for ingestion.queue. size The default queue size is 1024. This variable also specifies the number of rows for each partition. Increasing the queue size results in an increase in the memory consumption by the replication process and you may need to increase the pipelines_ cdc_ java_ heap_ size. -
max.: Specifies the maximum number of rows of data fetched from the remote source in a single iteration (batch).batch. size The default batch size is 512. max.must be lower thanbatch. size max..queue. size -
poll.: Specifies the interval for polling of remote sources if there were no new records in the previous iteration in the replication process.interval. ms The default interval is 500 milliseconds. -
snapshot.: Specifies the snapshot mode for the pipeline.mode It can have one of the following values: -
"initial"(Default): Perform a full snapshot first and replay CDC events created during the snapshot.Then, continue ingestion using CDC. -
"incremental": Start the snapshot operation and CDC simultaneously. -
"never": Skip the snapshot, and ingest changes using CDC.
Refer to CDC Snapshot Strategies for more information.
-
Replication Strategies
Use one of the following methods to create the required components for data ingestion.
Replicate MongoDB® Collections As Is
To replicate or migrate MongoDB® collections as is, use the CREATE {TABLES | TABLE} AS INFER PIPELINE SQL statement.
Apply Transformations or Ingest a Subset of Columns
To apply transformations or ingest only a subset of collections, manually create the required tables, stored procedure, and pipelines:
-
Run the
CREATE {TABLES | TABLE} AS INFER PIPELINESQL statement to infer the schema of the MongoDB® collection(s) and automatically generate templates for the relevant table(s), stored procedure(s), and aggregator pipeline(s). -
Use the automatically-generated templates as a base to create a new table(s), stored procedure(s), and pipeline(s) for custom transformations.
To inspect the generated table(s), stored procedure(s), and pipeline(s), use the SHOW CREATE TABLE,SHOW CREATE PROCEDURE, andSHOW CREATE PIPELINEcommands, respectively.After running the SHOWcommands, you can drop the templates and then recreate the same components with custom transformations.Using the automatically-generated templates:
-
Create table(s) in SingleStore with a structure that can store the ingested MongoDB® collection.
Refer to CREATE TABLE for more information. -
Create stored(s) procedure to map the MongoDB® collection to the SingleStore table and implement other transformations required.
Refer to CREATE PROCEDURE for information on creating stored procedures. -
Create pipeline(s) to ingest the MongoDB® collection(s) using the
CREATE AGGREGATOR PIPELINESQL statement.Refer to Parameters for a list of supported parameters.
Refer to CREATE PIPELINE for the complete syntax and related information. Note: The CDC feature only supports
AGGREGATORpipelines.
-
Refer to Syntax for information on CREATE {TABLES | TABLE} AS INFER PIPELINE SQL statement.
CDC Snapshot Strategies
SingleStore supports the following strategies for creating snapshots:
-
Perform a full snapshot before CDC (
"snapshot.):mode":"initial" The pipeline captures the position in the oplog and then performs a full snapshot of the data.
Once the snapshot is complete, the pipeline continues ingestion using CDC. This strategy is enabled by default. If the pipeline is restarted while the snapshot is in progress, the snapshot is restarted from the beginning. If the initial snapshot is large in size and the deployment is prone to restarts or connection issues from the source, SingleStore recommends using the
incrementalsnapshot mode.Note that the incrementalsnapshot mode is slower than theinitialmode.For faster data ingestion when the initial historical data is large in size, manually perform the snapshot and capture changes using the nevermode.To use this strategy, set
"snapshot.in themode":"initial" CONFIGJSON.Requirement: The oplog retention period must be long enough to maintain the records while the snapshot is in progress.
Otherwise, the pipeline will fail and the process will have to be started over. -
CDC only (
"snapshot.):mode":"never" The pipeline will not ingest existing data, and only the changes are captured using CDC.
To use this strategy, set
"snapshot.in themode":"never" CONFIGJSON. -
Perform a snapshot in parallel to CDC (
"snapshot.):mode":"incremental" The pipeline captures the position in the oplog and starts capturing the changes using CDC.
In parallel, the pipeline performs incremental snapshots of the existing data and merges it with the CDC records. Although this strategy is slower than performing a full snapshot and then ingesting changes using CDC, it is more resilient to pipeline restarts. To use this strategy, set
"snapshot.in themode":"incremental" CONFIGJSON.Requirement: The oplog retention period must be long enough to compensate for unexpected pipeline downtime.
-
Manually perform the snapshot and capture changes using the CDC pipeline:
To use this strategy, set
"snapshot.in themode":"never" CONFIGJSON.-
Create a pipeline and then wait for at least one batch of ingestion to capture the oplog position.
-
Stop the pipeline.
-
Snapshot the data using any of the suitable methods, for example,
mongodump. -
Restore the snapshot in SingleStore using any of the supported tools, for example
mongorestore. -
Start the CDC pipeline.
This strategy provides faster data ingestion when the initial historical data is very large in size.
Requirement: The oplog retention period must be long enough to maintain the records while the snapshot is in progress.
Otherwise, the pipeline will fail and the process will have to be started over. -
Configure Ingestion Speed Limit using Engine Variables
Use the following engine variables to configure ingestion speed:
|
Variable Name |
Description |
Default Value |
|---|---|---|
|
|
Specifies a forced delay in row emission while migrating/replicating your tables (or collections) to your SingleStore Helios databases. |
|
|
|
Specifies the JVM heap size limit (in MBs) for CDC-in pipelines. |
|
In-Depth Variable Definitions
Use the pipelines_ engine variable to limit the impact of CDC pipelines on the master aggregator node.1000000.
Use the max. parameter in the CONFIG JSON to control the ingestion speed.max. to half of max..pipelines_ engine variable accordingly.INFORMATION_ table for information on pipeline batch performance.
Optimize CDC-in Pipelines
Pipelines and Extractors
CDC-in pipelines ("pipelines") are aggregator pipelines that run on the Master Aggregator (MA).
SingleStore recommends ingesting a limited number of tables using CDC-in pipelines.
Memory and Resource Consumption
Each extractor consumes a persistent amount of resources (approximately pipelines_ per extractor).
Note: Total memory consumption may be higher and includes memory usage by the static system memory, shared libraries, JVM heap, etc.
To reduce the resource consumption on the MA reduce the JVM heap size (pipelines_).
Note: If JVM heap size is reduced, you may also need to reduce the pipeline batch and queue size.
Troubleshooting
-
If the
CREATE {TABLES | TABLE} AS INFER PIPELINESQL statement returns an error, run theSHOW WARNINGScommand to view the reason behind the failure. -
To view the status of the pipelines, query the
information_table.schema. PIPELINES_ CURSORS Run the following SQL statement to display the status of the replication task: SELECT SOURCE_PARTITION_ID,EARLIEST_OFFSET,LATEST_OFFSET,LATEST_EXPECTED_OFFSET-LATEST_OFFSET as STATUS,UPDATED_UNIX_TIMESTAMPFROM information_schema.PIPELINES_CURSORS;The value in the
STATUScolumn indicates the following:-
1: Indicates that the snapshot is in progress and the pipeline is expecting more data. -
0: Indicates that the initial snapshot is complete and the pipeline is capturing changes using CDC.
Note: If
snapshot.is set tomode incremental, the pipeline performs incremental snapshots in parallel to capturing changes via CDC.In this case, the value 1in theSTATUScolumn indicates that the pipeline is performing incremental snapshots and capturing changes in parallel. -
-
To view pipeline errors, run the following SQL statement:
SELECT * FROM information_schema.PIPELINES_ERRORS; -
If a pipeline fails with an out of memory error in Java, either increase the heap size using the
pipeline_engine variable or reduce thecdc_ java_ heap_ size max.andqueue. size max.parameters in thebatch. size CONFIGclause.The heap size is limited by the memory available on the MA. SingleStore recommends setting the queue size as double of the batch size.
Example
Example 1 - Create Tables with Different Names from the Source Collection
To create tables in SingleStore with names that differ from the name of the source MongoDB® collection, use the following syntax:
CREATE TABLE <new_table_name> AS INFER PIPELINE AS LOAD DATALINK <link_name> '<source_db.source_collection>' FORMAT AVRO;
You can also use this command to import collections if a table with the same name already exists in SingleStore.
Example 2 - Use Regular Expressions to Include or Exclude Collections or Databases
The names of the databases or collections to include or exclude are specified using regular expressions.dbTest, use the following regular expression:
dbTest[.].*
-- OR --
dbTest\..*where,
-
dbTestmatches the exact stringdbTest. -
[.and] \.match the character dot (.), which represents the dot (.) in<database_notation.name>. <collection_ name> Note that
.is a special character in regular expressions, and to match the character.it must either be escaped (\.) or specified as a literal character ([.).] -
.matches any sequence of characters, because the dot (* .) matches any single character and the asterisk (*) matches zero or more occurrences of any character.
Here's a sample CREATE LINK statement to include all the collections in the dbTest database, for example, dbTest., dbTest., dbTest., etc.
CREATE LINK mongoRepl AS MONGODBCONFIG '{"mongodb.connection.string": "mongodb+srv://cluster0.mongodb.net/","collection.include.list": "dbTest\..*","mongodb.ssl.enabled": "true","mongodb.authsource": "admin"}'CREDENTIALS '{"mongodb.user": "<username>","mongodb.password": "<password>"}';
To specify the collections or databases to include or exclude from the replication task, use either (or a combination) of the following parameters: collection., collection., database., or database..
Last modified: