Building a New Application
On this page
Welcome to SingleStore Helios! We put together a guide to help you build a new application using SingleStore.
-
Preparing your data for SingleStore
-
Interacting with SingleStore
-
Designing your SingleStore tables to be optimized for your applications
-
Importing data from your originating database
-
Optimizing your queries for your applications
-
Connecting your application to SingleStore
Tutorial Outline
This tutorial is divided into the following sections:
Getting Started
-
Benefits of leveraging S2MS for your application
-
Why SingleStore is a developer’s first choice for applications
-
What kinds of apps are developers building?
Preparing Your Data for SingleStore
SingleStore Database Administration
-
Cloud Portal
-
Drivers
-
MySQL Workbench
-
MySQL Command Line
Designing Your Tables
-
Data Types
-
Designing a schema for an application
-
Sharding for application workloads
-
Sort keys for application workloads
-
Reference Tables
-
Ingesting Data
-
Using SingleStore Pipelines
-
Using
INSERTStatements
Testing Your Queries
-
Run queries
-
Visual Explain
-
Concurrency test your queries
Connecting to Your Application Development Tools
-
Code samples to connect to SingleStore
Getting Started
We are excited for you to get started building your first application with SingleStore Helios (S2MS).
Some terminology used in this guide:
-
App/Application: Web- or mobile-based, customer or internal facing application.
-
Object storage: Cloud-based data repository.
There are a few key steps to building the database for your first app, and here's how SingleStore can help:
-
Design your schemas - Make a few simple, straightforward selections on how your data is distributed and sorted to set yourself up for millisecond response
-
Load your data - Five lines of SQL to ingest thousands of records per second
-
Test your queries - Simple Cloud Portal interface to run queries, with in-depth visual profiling tool to make them fast
-
Connecting to your app - We offer many connectivity options, no matter where you're building your first app
These steps are applicable to all of the applications that have been built on SingleStore.
Here are a few ideas to help you brainstorm on some concepts to embed within your app:
-
Geospatial apps for real-time tracking and fencing using points, paths, and polygons
-
Analytical apps with complex aggregations and real-time updates
-
Mobile apps with rapid queries and high concurrency
Let's get started by discussing some of the basic things to consider when bringing your data over from one of these databases.
Sample Architecture
Here's example of how SingleStore is used by many to give immersive, responsive experiences to their customers.
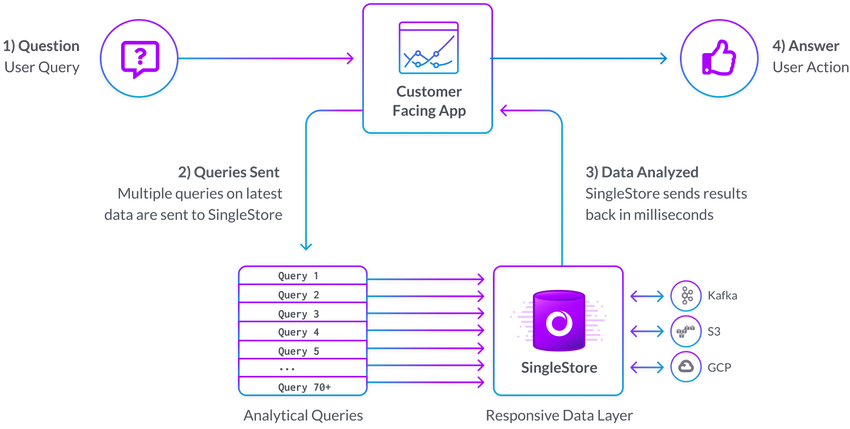
Users just getting started may already have data being generated by their application.
Preparing Your Data for SingleStore
SingleStore has simple, powerful methods of bringing data in from object storage and streaming data sources.
That said, we realize if you're just getting started you may not have bulk or streaming data sources set up.
Database Administration
Now that we have identified our data source, let's talk a bit about how we'll interact with SingleStore.
Cloud Portal
When you signed up for SingleStore, you got access to our Cloud Portal, including tools such as the SQL Editor and Visual Explain.
If you to use third-party tools, make sure that you have the appropriate client drivers prior to using other database administration tools.
MySQL Workbench
If you're coming from MariaDB or MySQL, you may already be comfortable with Workbench.
Note
When defining your connection, you will need to go to the Advanced tab and insert defaultAuth=mysql_ in the "Others:" field to ensure proper authentication.
MySQL Command Line
Within your Cloud Portal, your workspace details will include a MySQL Command section.
Note
When defining your connection, you will need to enter this at the MySQL command line: --defaultAuth=mysql_ to ensure proper authentication.
Designing Your Tables
At this point, you should be using SingleStore SQL Editor or Studio, or some other MySQL client to work with your cloud database.
By default within SingleStore Helios, database tables are created using our Universal Storage format (i.
Data Types
If you're familiar with relational databases, you may not need too much guidance on data types.
In addition to data types traditionally supported in relational databases, SingleStore also supports JSON and geospatial data types.
Shard Key
This key determines how data is distributed across the database workspace, and is critical to ensure that your data isn't skewed.
We offer free training on sharding if you'd like to learn more!
So how do I pick a shard key best for my application workload?
-
If you have a primary key, make sure the shard key is a subset of it (because cardinality matters!).
-
If your application queries include frequent joins or filters on a specific set of columns, make sure the shard key is a subset of those.
-
Concurrency is very important with application workloads, so make sure your shard key allows your queries to be single partition, as explained below.
In this example, we use user_ as our shard key, which works nicely given its high cardinality as a part of this dataset.user_ will be maintained together, which will improve query response time.
CREATE TABLE clicks (click_id BIGINT AUTO_INCREMENT,user_id INT,page_id INT,ts TIMESTAMP,SHARD KEY (user_id),SORT KEY (click_id, user_id));
Columnstore Key
In addition to identifying your shard key, it's important to tell SingleStore how you would like to sort your data within each data segment.
So how do I pick a columnstore key best for my application workload?
-
If you have common filter columns, make sure those are in the columnstore key.
-
If you're inserting in order by some column, it's best to put that column first in the columnstore key.
-
Lower cardinality columns should be first in the columnstore key.
In this example, we use price as our sort key, so items are sorted in order of that column when queried.
CREATE TABLE products (ProductId INT,Color VARCHAR(10),Price INT,Qty INT,SORT KEY (Price),SHARD KEY (ProductId));
Reference Tables
If you have small, infrequently changing table(s) that are required for joins, consider making them Reference tables.
-
Reference tables are replicated to each leaf in the workspace ensuring data does not need to go across the network between partitions to join data.
-
Reference table commands need to be run from the endpoint listed in the Cloud Portal.
Data Ingest
Now for the fun part, ingesting data! This is where things may look a bit different to you compared to other databases, because SingleStore has this unique ingest capability called Pipelines that supports high-frequency, parallel ingest of data from sources like S3, Azure Blob, GCS, Kafka, etc.
SingleStore Pipelines
To use a Pipeline to import data into SingleStore, write a CREATE PIPELINE statement using our SQL Editor or a MySQL client.
A few things to consider:
-
Make sure that your security settings in your blob storage will allow for access from SingleStore.
For example, AWS S3 security settings can be found here. -
Make sure your buckets are not public, but you should be able to obtain an access and secret key using the AWS doc here.
-
You can use wildcard notation when identifying your files from within the bucket.
Here's an example of a CREATE PIPELINE statement:
CREATE PIPELINE libraryAS LOAD DATA S3 'my-bucket-name'CONFIG '{"region": "us-west-1", "suffixes": ["csv"]}'CREDENTIALS '{"aws_access_key_id": "your_access_key_id", "aws_secret_access_key": "your_secret_access_key"}'INTO TABLE `classic_books`FIELDS TERMINATED BY ',';
GCP Documentation:
Load Data from Google Cloud Storage (GCS) Using a Pipeline
Azure Documentation:
Insert Statements
Perhaps instead of bulk loading data, you'd like to write directly from your application.
Testing Your Queries
Here are some helpful hints for testing your queries.
Running Queries
Hopefully at this point you have your data in SingleStore.
Visual Explain
One great feature of Cloud Portal is our Visual Explain functionality.
the visual explanation or profiling of your query.
Once you identify a bottleneck, you should be able to make changes either to your schema or to your query itself in order to improve speed.
You can manually (non-visually) run EXPLAIN or PROFILE from any client; see the links above for details on the commands.
Benchmarking
At SingleStore, we've developed an easy-to-use tool for benchmarking called dbbench.
Once you've installed the packages to your host machine, you can walk through this tutorial.svc-xxx-dml.).3306, as listed.
Connecting to Your Application Development Tools
We've created tutorials on how to connect to SingleStore using a variety of different frameworks, which you can find in the list below.
The tutorials below show how to leverage both SingleStore Helios and SingleStore Self-Managed (our self-managed product).
JavaScript / Node
SQL: https://github.
Stored Procedures: https://github.
C#
SQL: https://github.
Stored procedures: https://github.
Java
SQL: https://github.
Stored procedures: https://github.
Go
SQL: https://github.
Stored procedures: https://github.
Ruby
SQL: https://github.
Stored procedures: https://github.
Last modified: February 23, 2024