Augmenting Your Data Warehouse to Accelerate BI
On this page
Welcome to SingleStore Helios! We put together a guide to help you augment your data warehouse by migrating some of your BI workloads to SingleStore.
-
Preparing your data from your existing data warehouse
-
Interacting with SingleStore
-
Designing your SingleStore tables to accelerate your dashboards
-
Incorporating streaming data with SingleStore
-
Optimizing your queries for your dashboards
-
Connecting your dashboard to SingleStore
Tutorial Outline
This tutorial is divided into the following sections:
Getting Started
-
Benefits of leveraging SingleStore Helios for your BI dashboard
-
Why users leverage SingleStore to augment their existing data warehouse technologies
-
-
What to consider when bringing your data from:
-
Snowflake, Redshift, BigQuery, Synapse
-
AWS S3, Google CS, Azure, Kafka
-
-
What to consider when designing your database coming from:
-
MySQL, MariaDB, Postgres
-
Sample Architecture
Preparing Your Data for SingleStore
Database Administration
-
Cloud Portal
-
Drivers
-
MySQL Workbench
-
MySQL Command Line
Designing Your Tables
-
Data types
-
Designing a schema for an application
-
Sharding for application workloads
-
Sort keys for application workloads
-
Reference Tables
-
Data Ingest
-
How this may be different from ingesting directly to the data warehouse
-
Using SingleStore Pipelines
-
Using INSERT Statements
Testing Your Queries and Performance
-
Run queries
-
Visual Explain
-
Concurrency test your queries using
dbenchbased on app expectations
Writing Back to Your Application
Connecting Your BI Tools
-
Connectivity samples for Tableau, Power BI, Looker
Getting Started
We are excited for you to get started accelerating your BI dashboards by augmenting your cloud data warehouse with SingleStore Helios (SSMS).
Some terminology used in this guide:
-
App/Application: Web- or mobile-based, customer or internal facing application.
-
Dashboard: Visual analytics displayed either through commercial business intelligence tools or custom-built solutions.
-
Object storage: Cloud-based data repository.
Data warehouse users often find improved query latency and concurrency support using SingleStore Helios as the data store directly fueling their dashboards, while retaining their data warehouse for long term storage.
Let’s get started by discussing some of the basic things to consider when bringing your data over from one of these data warehouses.
Things to Consider
For users starting with a database already hosted in a cloud provider like AWS, Azure, or GCP, you may already have your data sitting in object storage (if not, we walk through how to do this later).
Now, of course, every database is different.
Things to know, regardless of your current platform:
-
SingleStore Helios can be deployed in any of the three major clouds, in any region – so you don’t have to worry about moving regions.
-
Cloud Enterprise Data Warehouses (EDWs) typically leverage ANSI SQL, and SingleStore does too.
However, SingleStore leverages MySQL syntax so there may be some modifications required. SingleStore is also ACID compliant.
Things to know for specific databases:
Snowflake
Users often use SingleStore Helios in conjunction with Snowflake to achieve improve concurrency and ingest SLAs at a lower overall TCO.
Redshift
-
Users often use SingleStore Helios in conjunction with Redshift to improve overall query latency for workloads with transactions and analytics.
-
Many users come to SingleStore Helios after they have reached the Redshift column limitation as well.
-
Redshift’s "leader nodes" and "compute nodes" correspond to SingleStore Helios’s aggregator nodes and leaf nodes.
Aggregators handle client communication and query orchestration, and leaf nodes manage data and compute power. You don’t need to know too much here given that this is a managed service, but you’ll see the node types denoted within the "Nodes" section of the Cloud Portal.
BigQuery
Users typically find SingleStore Helios to be faster in overall ingest speeds and query latency with concurrency, but may find BigQuery simpler to implement with the overall GCP stack.
Azure Synapse
Synapse’s "control nodes" and "compute nodes" correspond to SingleStore Helios’s "aggregator nodes" and "leaf nodes".
Sample Architectures
Many of our users experience slow dashboard response times when overwhelming their data warehouses with various different speeds and sizes of data.
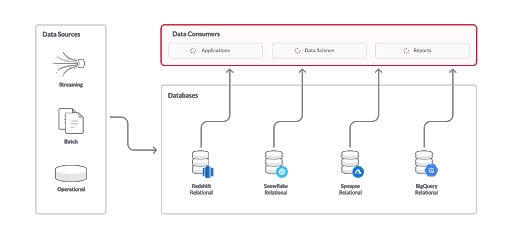
Keeping those data warehouses in place and augmenting them with a high performance database built for fast ingest and concurrency helps our users not only save money, but deliver a stellar user experience.
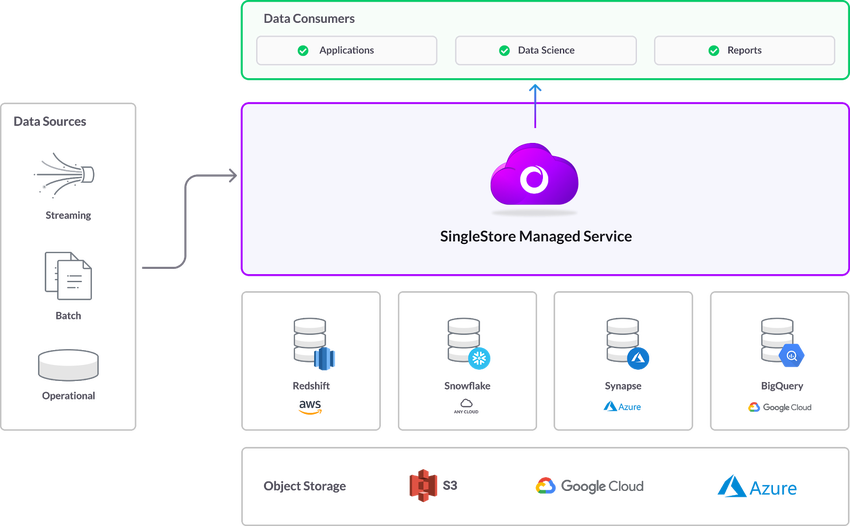
Preparing Your Data for SingleStore
SingleStore has simple, powerful methods of bringing data in from object storage.
Is your data already in cloud storage? Feel free to move on to the next section.
Existing Managed Cloud Databases:
-
Synapse to Blob Storage
For other databases that you’re looking to migrate, you can still export that data to CSV, JSON, etc.SELECT . from your existing database.
If you are importing data from MySQL or MariaDB, you can perform a simple mysqldump as listed in Transition from MySQL to SingleStore Helios.
Don’t want to do a bulk import? That’s fine too! After we discuss schema design, we’ll walk you through connecting directly from your application and writing data.
Database Administration
Now that we have identified our data source, let’s talk a bit about how we’ll interact with SingleStore.
When you signed up in Cloud Portal, you got access to our SQL Editor and Visual Explain tools.
Ensure that you have the appropriate client drivers prior to using other database administration tools.
MySQL Workbench
If you’re coming from MariaDB or MySQL, you may already be comfortable with Workbench.
Note: When defining your connection, you will need to go to the Advanced tab and insert defaultAuth=mysql_ in the "Others:" field to ensure proper authentication.
MySQL Command Line
Within your Cloud Portal, your workspace details will include a MySQL Command section.
Note: When defining your connection, you will need to enter this at the MySQL command line: --defaultAuth=mysql_ to ensure proper authentication.
Designing Your Tables
At this point, you should be using the SQL Editor or some other MySQL client to work with your cloud database.
By default within SingleStore Helios, database tables are created using our Universal Storage format (i.
Data Types
If you’re familiar with relational databases, you may not need too much guidance on data types.
In addition to data types traditionally supported in relational databases, SingleStore also supports JSON and geospatial data types.
Shard Key
This key determines how data is distributed across the database workspace, and is critical to ensure that your data isn’t skewed.
-
Snowflake users may be familiar with micro-partitioning and workspaceing to distribute data.
If you’ve perhaps found these difficult to maintain on ever-changing data, you are in the right place. -
Redshift users would be familiar with the various mechanisms listed here for data distribution across a workspace.
-
BigQuery users will be familiar with the concept of sharding from
partitioned tables
. -
Synapse users will be familiar with the concept of sharding, though SingleStore Helios gives you a bit more flexibility here on data distribution.
So how do I pick a shard key best for my application workload?
-
If you have a primary key, make sure the shard key is a subset of it (because cardinality matters!).
-
If your BI queries include frequent joins or filters on a specific set of columns, make sure the shard key is a subset of those (in both tables, for joins).
-
For highly concurrent workloads, make sure your shard key allows your queries to be single partition (i.
e. , join or filter columns within shard key).
In this example, we use user_ as our shard key, which works nicely given its high cardinality as a part of this dataset.user_ will be maintained together, which will improve query response time.
CREATE TABLE clicks (click_id BIGINT AUTO_INCREMENT,user_id INT,page_id INT,ts TIMESTAMP,SHARD KEY (user_id),SORT KEY (click_id, user_id));
Columnstore Key
In addition to identifying your shard key, it’s important to tell SingleStore how you would like to sort your data within each data segment.
If you’re familiar with BigQuery, you may note that this is similar to the concept of workspaceing.
So how do I pick a columnstore key best for my BI workload?
-
BI dashboards often require lots of filtering.
If you have common filter columns, make sure those are in the columnstore key. -
If you’re inserting in order by some column, it’s best to put that column first in the columnstore key.
-
Lower cardinality columns should be first in the columnstore key.
In this example, we use price as our sort key, so items are sorted in order of that column when queried.
CREATE TABLE products (ProductId INT,Color VARCHAR(10),Price INT,Qty INT,SORT KEY (Price),SHARD KEY (ProductId));
Reference Tables
If you have small, infrequently changing table(s) that are required for joins, consider making them Reference Tables.
-
Reference tables are a convenient way to recreate dimension tables that you may use in MySQL, MariaDB, or PostgreSQL.
-
Reference tables are replicated to each leaf in the workspace ensuring data does not need to go across the network between partitions to join data.
-
Reference table commands need to be run from the endpoint listed in the Cloud Portal.
Manage Database Users
Add a Database User
Database users are created automatically for all SingleStore Helios users who are granted access to a workspace group.
Refer Authenticate via Browser-based SSO using JWTs for more information about authentication from third-party clients.
Database users can also be added by using the CREATE USER command.GRANT command cannot be used to add a new user since auto user creation by using the GRANT command is deprecated and the NO_ variable is enabled by default.
If you have invited another SingleStore Helios user to join your organization, refrain from adding a database user with the same SingleStore Helios email address (i.
As the admin user is not always a workspace log-in option for all organization members, SingleStore recommends adding a separate database user for each organization member.
Change a Database User Password
The database admin password is configured when the workspace is first created.admin by default.
To change this password, navigate to the Deployments in the left navigation, and then select Access > User Access.
Note: You must have SUPER /admin privileges to change another user’s password using the GRANT command.
Use the SET PASSWORD command to change a database user's password.
SET PASSWORD FOR 'username'@'host' = PASSWORD('password');
Remove a Database User
To remove a database user, use the DROP USER command.
DROP USER '<user>'@'<host>'
Inspect Database User Permissions
You can view grants and permissions by querying information_.
You can also view grants for a user by running SHOW GRANTS:
SHOW GRANTS FOR user@domain;
Set a Login Attempt Lockout Policy for a Database User
You can specify the number of times a user can enter an incorrect password before they are locked out of the system.
This feature can be enabled per user or per role, in which case every user belonging to that role will be subject to failed login attempt lockout.
Enable the Lockout Policy
To enable the lockout policy:
Set bothFAILED_ and PASSWORD_ for the user or role.FAILED_ is the number of failed attempts before the account is locked, for example: 4.PASSWORD_ is the number of seconds a locked out account must wait before reattempting to log in.
Note
You must set both FAILED_ and PASSWORD_ to enable the feature.
Enable the lockout feature at 4 failed attempts, with a lockout time of 4 hours (14400 seconds) when creating a user:
CREATE USER user1 WITH FAILED_LOGIN_ATTEMPTS = 4 PASSWORD_LOCK_TIME = 14400;
Enabling the feature for a role:
CREATE ROLE general WITH FAILED_LOGIN_ATTEMPTS = 4 PASSWORD_LOCK_TIME = 14400;
If a user is associated with more than one role with different password lock times, the larger PASSWORD_ value is applied.
If a user and a role the user is tied to have conflicting FAILED_ settings, the lower value is applied.
Update Lockout Settings
If the PASSWORD_ value is updated for a role or user, the new setting applies to currently locked accounts.PASSWORD_ is then set to 4 hours, the new limit is enforced and the account will be unlocked 4 hours after it was locked.
If the FAILED_ setting for a locked out user is updated to be higher than the current setting, the user is unlocked.FAILED_ setting.
Unlock a Locked Account
To unlock a locked account:
Use the ALTER USER command and specify ACCOUNT UNLOCK.
ALTER USER user ACCOUNT UNLOCK;
Testing Your Queries
Here are some helpful hints for testing your queries.
Running Queries
Hopefully at this point you have your data in SingleStore.
Visual Explain
One great feature of SingleStore Helios is Visual Explain.
Once you identify a bottleneck, you should be able to make changes either to your schema or to your query itself in order to improve speed.
You can manually (non-visually) run EXPLAIN or PROFILE from any client; see the links above for details on the commands.
Benchmarking
At SingleStore, we've developed an easy-to-use tool for benchmarking called dbbench.
Once you've installed the packages to your host machine, you can walk through this tutorial.svc-xxx-dml.).3306, as listed.
Writing Back to Your Application
In the Sample Architectures section, we shared some general practices that our users have employed when augmenting their data warehouse environment with SingleStore.
The best way to write to a cloud data warehouse from SingleStore is again via object storage (i.SELECT… INTO… in order to take the output of a given query and drop it into object storage.
Connecting Your BI Tools
You’ve likely already selected an analytics partner, so we won’t go too deep into the similarities and differences between them.
In these examples, you’ll be using your endpoint here provided in the Cloud Portal, along with the credentials you used when spinning up your workspace.Firewall
section of the Cloud Portal allows communication between your BI and SingleStore Helios environments.
Tableau
Documentation: Connect with Tableau Desktop
Notes: Tableau has a limitation of auto updates at most one per hour, so you may not see your real-time data updating within your dashboard by the second.
Power BI
Documentation: Connect with Power BI
Notes: Make sure you are using DirectQuery mode to truly harness the power of SingleStore and all of the data you have stored.
Looker
Documentation: Connect with Looker
Notes: Looker allows dashboards to update up to the second, so be sure to watch the video in (b) to see how to configure that.
Additional Analytics and BI Tools
Last modified: October 28, 2024